No. 004·May 8, 2026·6 min read
Introducing the Scira CLI harness, plus a first public benchmark sweep
Headless research CLI on Flue and a 19-question grounded-QA suite, both on GitHub. Sweep with eight model configs on Parallel and Exa: Parallel leads on mean score and mean latency; per-cell charts in the post.
The Scira CLI harness is open source with the benchmark harness used to vet grounded research against Scira’s bar.
It is a headless take on Scira web research: plan queries, hit search backends, fetch selected pages, synthesize with citations, emit a source ledger for audit. Not production (no app shell, auth, or live routing), but the same pipeline shape, tuned for scripts and repeatable grids.
What the harness is#
Single-binary CLI on Bun and the Flue agent runtime. No UI and no service to deploy. API keys wire search (Parallel, Exa, Firecrawl) and models (xAI, OpenAI, Anthropic, Cloudflare Workers AI, OpenRouter). Agent: .flue/agents/research.ts; system prompt: .flue/roles/researcher.md, both editable in-tree. The intent is to keep agent behavior close to Scira-style research while the product ships faster than this codebase.
Example invocation:
bun run src/cli.ts research "compare Scira and Perplexity" \
--provider parallel \
--model openai/gpt-4.1-miniPipeline per call:
- Plan: rewrite the prompt into 1 to N search queries.
- Search: queries hit the configured provider (
parallel,exa, orfirecrawl); ranked results return. - Fetch (selective):
fetch_linksretrieves full page content for URLs the agent selects. Backend: Parallel Extract, ExagetContents, or Firecrawlscrape, matched to the search provider. - Synthesize: the model emits Markdown with inline citations.
- Source ledger: structured footer listing every query, every fetch, each snippet, and the citation each snippet supports. Auditable by construction.
Optional shortcuts: --no-synthesis (sources only, for retrieval-only evaluation). --sandbox plus DAYTONA_API_KEY runs Python in a Daytona microVM when computation matters. --json emits structured runs (benchmark mode consumes this shape).
Benchmark mode reuses the same agent, fixture-driven:
bun run src/cli.ts benchmark \
--suite benchmarks/research-smoke.json \
--providers parallel,exa \
--models xai/grok-4.20-0309-non-reasoning \
--concurrency 4The subcommand walks (suite case × provider × model), runs each cell through identical agent + prompt template, grades against an in-file rubric. Output is a Markdown log or JSON.
Controlled variables:
- Same agent, same prompt, every cell. Only
providerandmodelvary. No per-model prompt tuning. - Live web, no caching. Latency and sources vary run to run; scores are not frozen reproducibility chips.
- Strict, deterministic grader. Rubric lives in the suite file. Pass = 100/100. No LLM-as-judge.
Setup#
- Suite:
research-smoke, 19 source-backed QA prompts in four buckets (SimpleQA-style recall, BrowseComp-style hunts, GAIA-style structure, small Flue / ops checks). - Search providers: Parallel and Exa.
- Models: eight configs: Grok 4.1 Fast, Grok 4.20, and Grok 4.3 (xAI ids as in the repro line); Kimi K2.6, Nemotron 3 120B, and Gemma 4 26B on Cloudflare Workers AI. Repro commands use each provider’s CLI model id.
- Total runs: 16 (provider, model) cells × 19 cases = 304 graded calls.
- Concurrency: 4. Date: 2026-05-08.
- Grader: in-harness rubric on facts, expected sources, citation hygiene, adversarial behavior under negative prompts. Pass threshold 100/100; partial scores often land 70 to 92.
Committed log for this sweep: docs/benchmark-runs/scira-bench-08052026-2.md in scira-cli-harness. Other runs can pass --out under benchmark-results/ (gitignored). Summary table:
Findings#
F1. Accuracy#
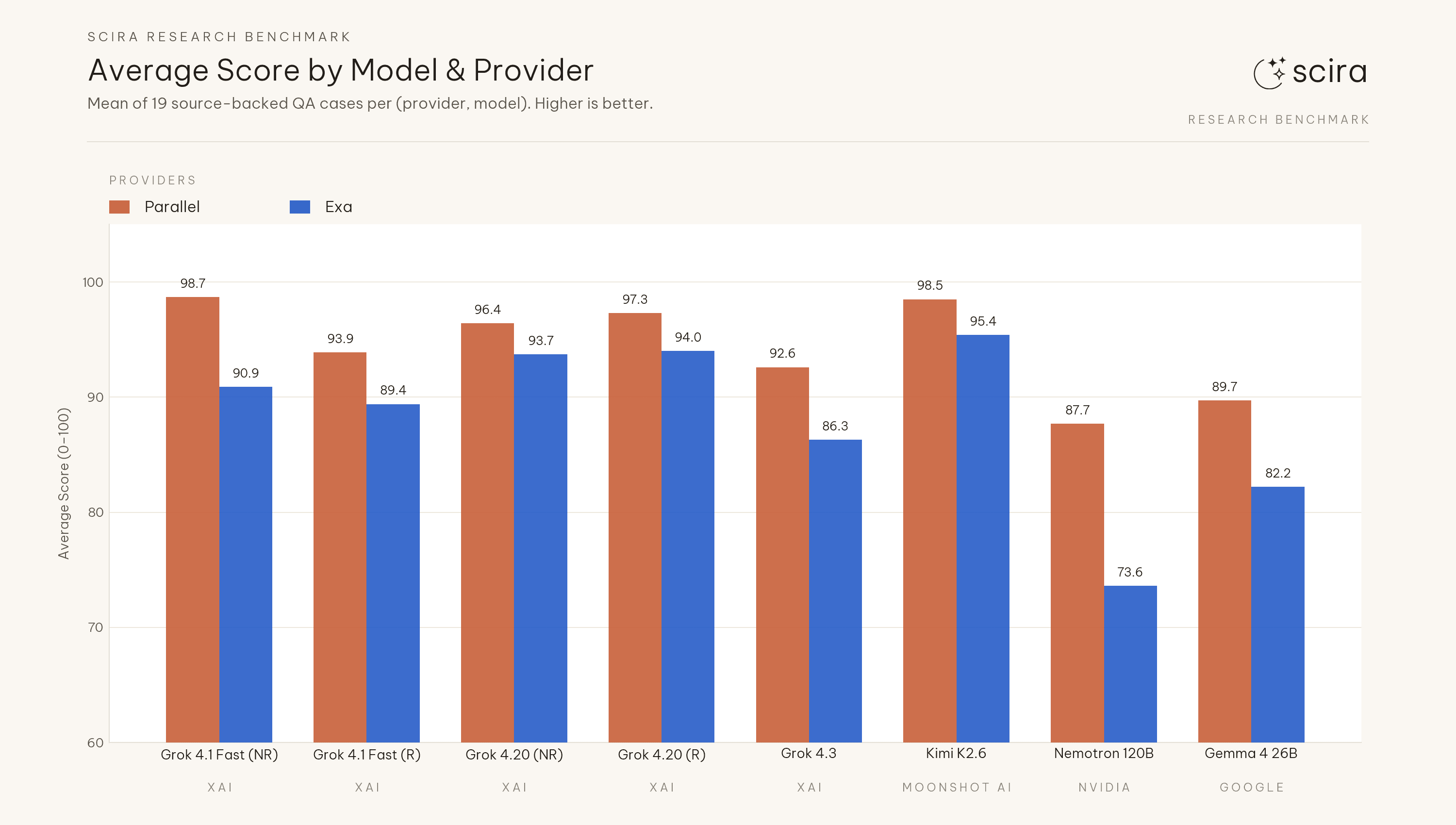
Mean score across the eight model configurations: 94.4 (Parallel) vs 88.2 (Exa), about 6.2 points apart. Each of the eight models scored higher on Parallel than on Exa in this pairing. Summed full passes (of 19) across those eight rows: 104 (Parallel) vs 82 (Exa).
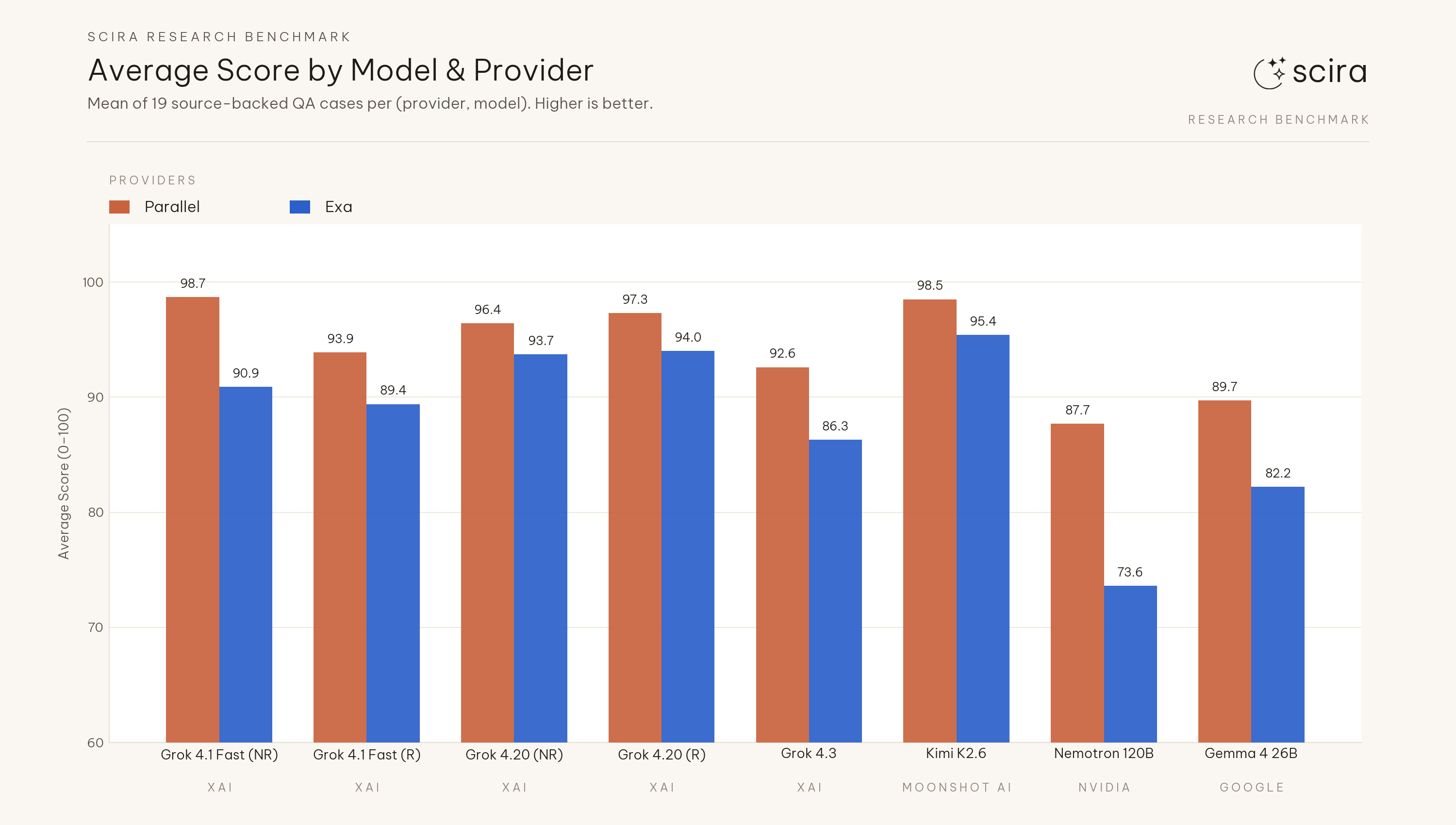 Average score by model and provider
Average score by model and provider
F2. Deepest cells sit on Start Commands#
Minimum scores in the grid still sit on flue-start-commands (Start Commands): 29 on Exa for Grok 4.1 Fast (NR), 30 on Parallel for Nemotron 3 120B, 33 on Parallel and Exa for Gemma 4 26B (Exa Grok 4.1 Fast (R) also 33), and 30 on Exa for Grok 4.3. The row spans up to 100 on some configs. That case grades CLI-style command usage under the suite rubric, so the floor reads as structured ops failures rather than weak browsing recall alone.
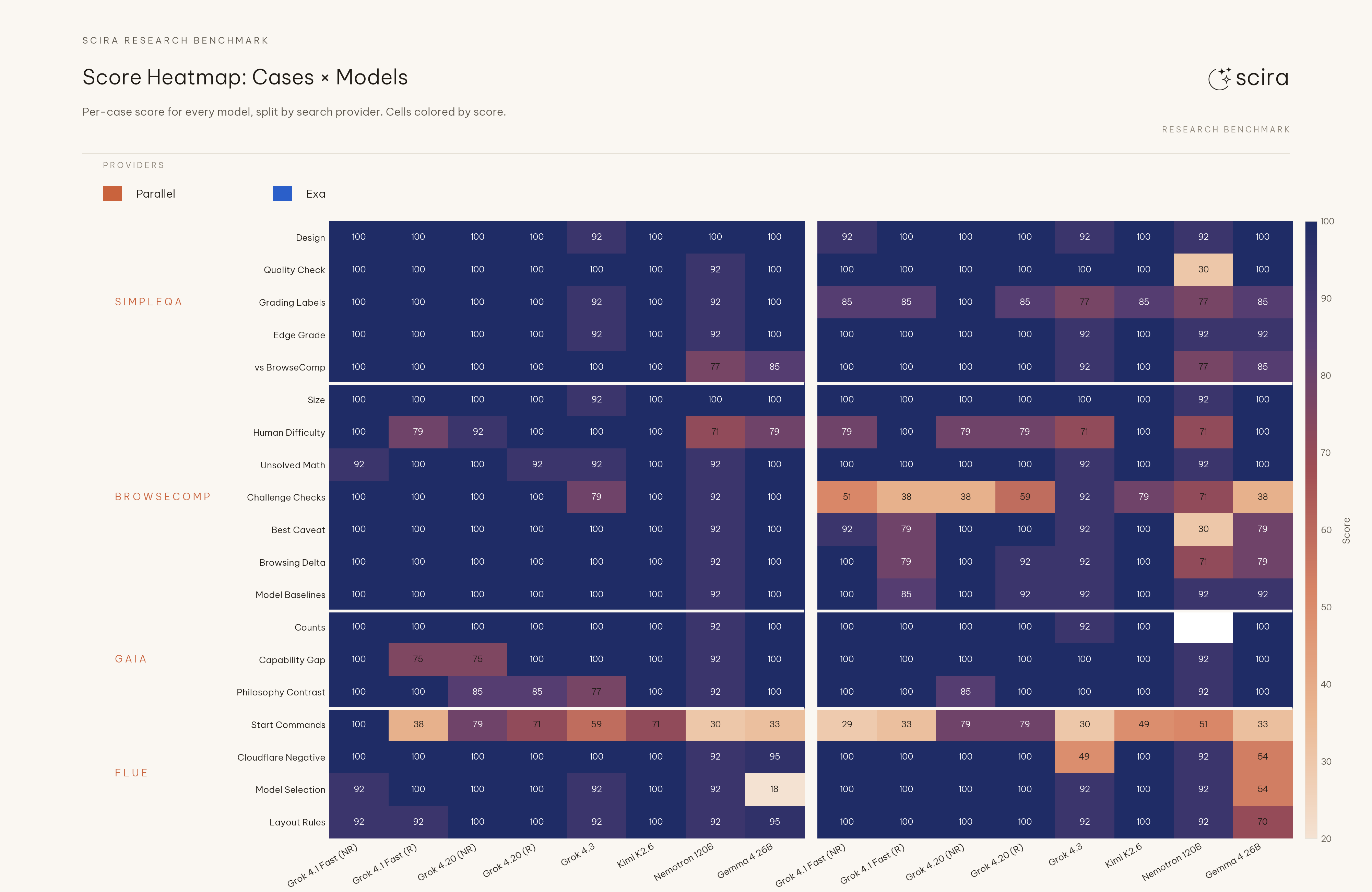 Score heatmap: cases by model, split by provider
Score heatmap: cases by model, split by provider
F3. Browsing-heavy prompts carry most of the Exa deficit#
Rollup across SimpleQA-style, BrowseComp-style, GAIA-style, and small ops checks: Exa loses the most ground where the task needs multi-page retrieval, not on short factual recall.
Concrete rows:
simpleqa-vs-browsecomp: Nemotron 77 and Gemma 85 match on both backends; Kimi 100 on both. Grok 4.3 scores 92 on Exa versus 100 on Parallel on that row; other xAI configs are at 100 on both sides in this run.browsecomp-human-difficulty: On Exa several xAI configs sit in the 71-79 band while Kimi and Grok 4.1 Fast (R) clear 100; on Parallel Nemotron 71 and Gemma 79 also sit below 92 on that row, so the split is no longer a clean Parallel-only floor.
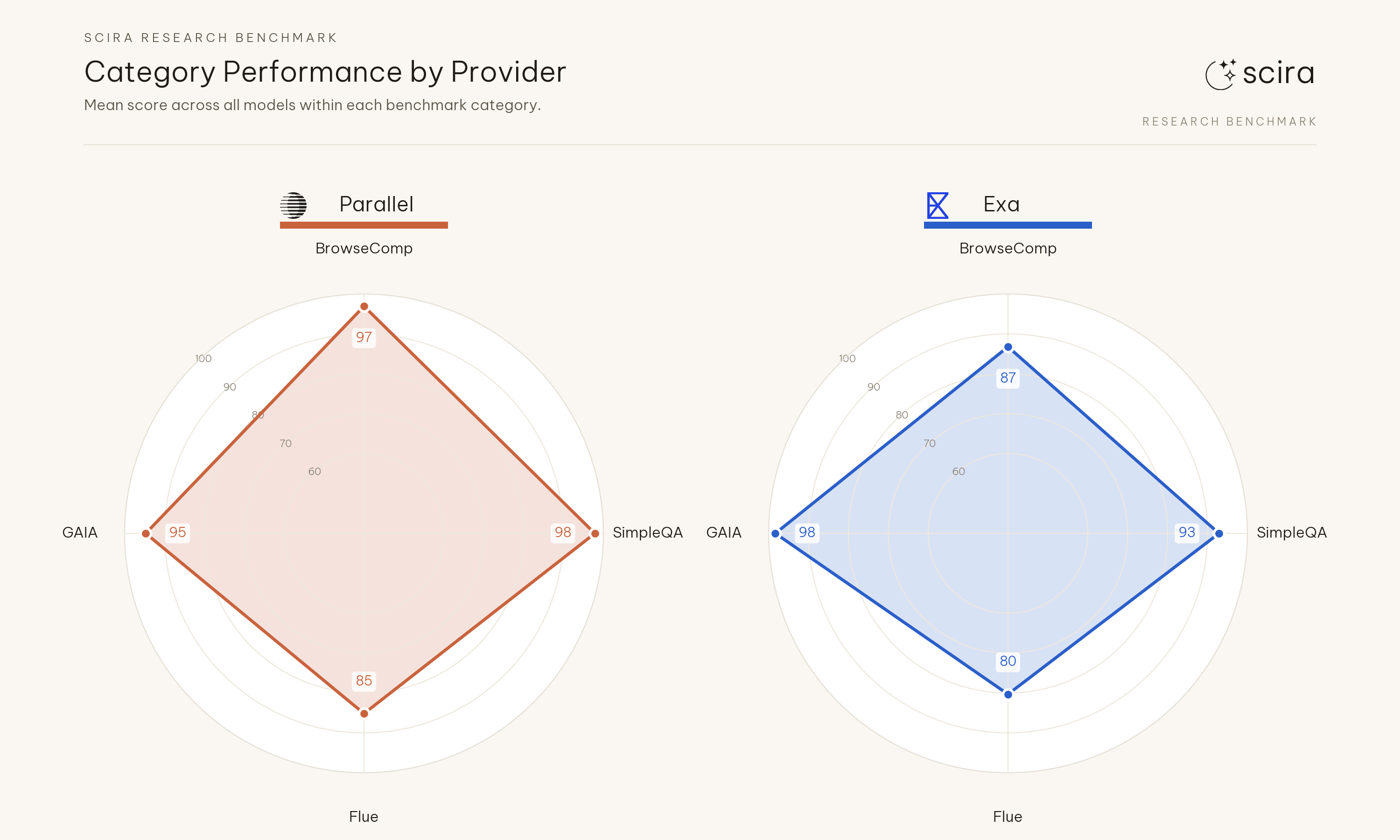 Category performance by provider
Category performance by provider
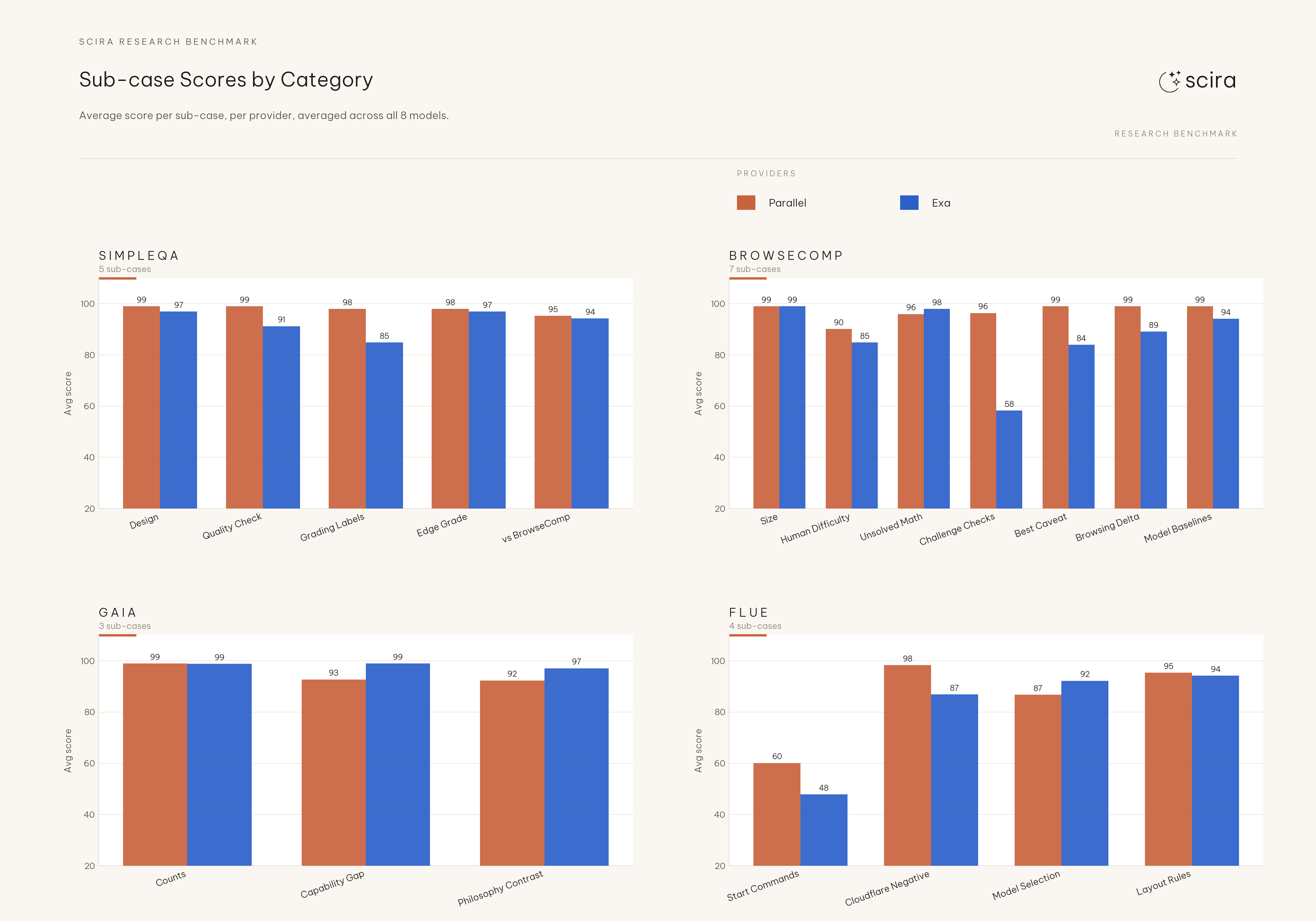 Sub-case scores by category
Sub-case scores by category
F4. Latency#
Mean of per-model mean durations: 31.8s (Parallel) vs 55.3s (Exa), about 42% faster on Parallel. Largest paired gap: Kimi K2.6 at 38.8s vs 113.0s with mean score still higher on Parallel. At the provider aggregate this sweep did not trade accuracy for slower runs on Exa. The scatter uses the full duration range on the horizontal axis and automatic label placement so every configuration stays readable.
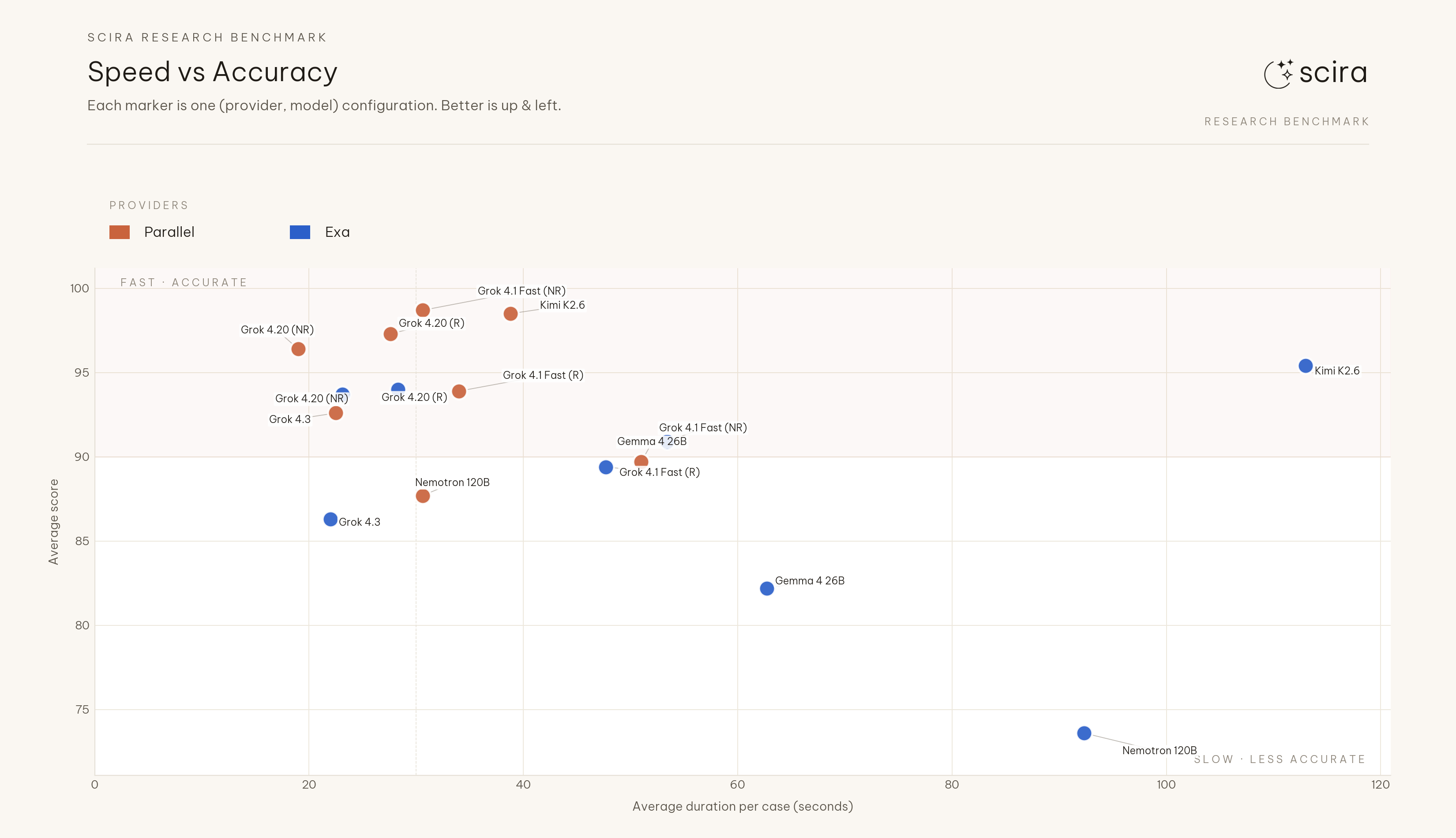 Speed vs accuracy scatter
Speed vs accuracy scatter
F5. Strongest cell in the table#
Grok 4.1 Fast (NR) on Parallel: 98.7 mean, 16/19 passes, 30.6s mean duration in this table (highest mean score in the sweep). Grok 4.20 (NR) on Parallel: 96.4 mean, 15/19 passes, 19.0s, a better latency position with a lower mean than Grok 4.1 Fast (NR). Pick between them depends on whether the product optimizes for peak mean score or wall clock on this suite.
F6. Open weights move more than Grok when search changes#
Parallel-to-Exa mean score drop on the five xAI configs in this run ranges up to about 7.8 points (Grok 4.1 Fast NR). Cloudflare-hosted open weights:
- Nemotron 3 120B: 87.7 to 73.6 (−14.1), passes 2 to 0.
- Gemma 4 26B: 89.7 to 82.2 (−7.5).
- Kimi K2.6: 98.5 to 95.4 (−3.1), smallest gap of the three.
Stronger models may absorb weaker retrieval with extra retrieval rounds and tighter citations; smaller models track retrieval quality more tightly. Logs carry query traces if anyone wants to dig.
F7. Reasoning mode moves opposite directions by backend#
Grok 4.20, non-reasoning vs reasoning:
- Parallel: 96.4 vs 97.3 (reasoning slightly higher).
- Exa: 93.7 vs 94.0 (reasoning slightly higher).
Same model ids and prompts; only search backend moves between rows. Reasoning adds latency on both backends in this suite; the accuracy delta between modes stays within about one point for Grok 4.20 here.
F8. Rankings split by provider#
Parallel (high to low mean): Grok 4.1 Fast (NR), Kimi K2.6, Grok 4.20 (R), Grok 4.20 (NR), Grok 4.1 Fast (R), Grok 4.3, Gemma 4 26B, Nemotron 3 120B.
Exa: Kimi K2.6, Grok 4.20 (R), Grok 4.20 (NR), Grok 4.1 Fast (NR), Grok 4.1 Fast (R), Grok 4.3, Gemma 4 26B, Nemotron 3 120B.
Nemotron 3 120B sits at the bottom on both backends in this run (2/19 passes on Parallel, 0/19 on Exa). Order below the headline tier should not be read across backends without controlling search.
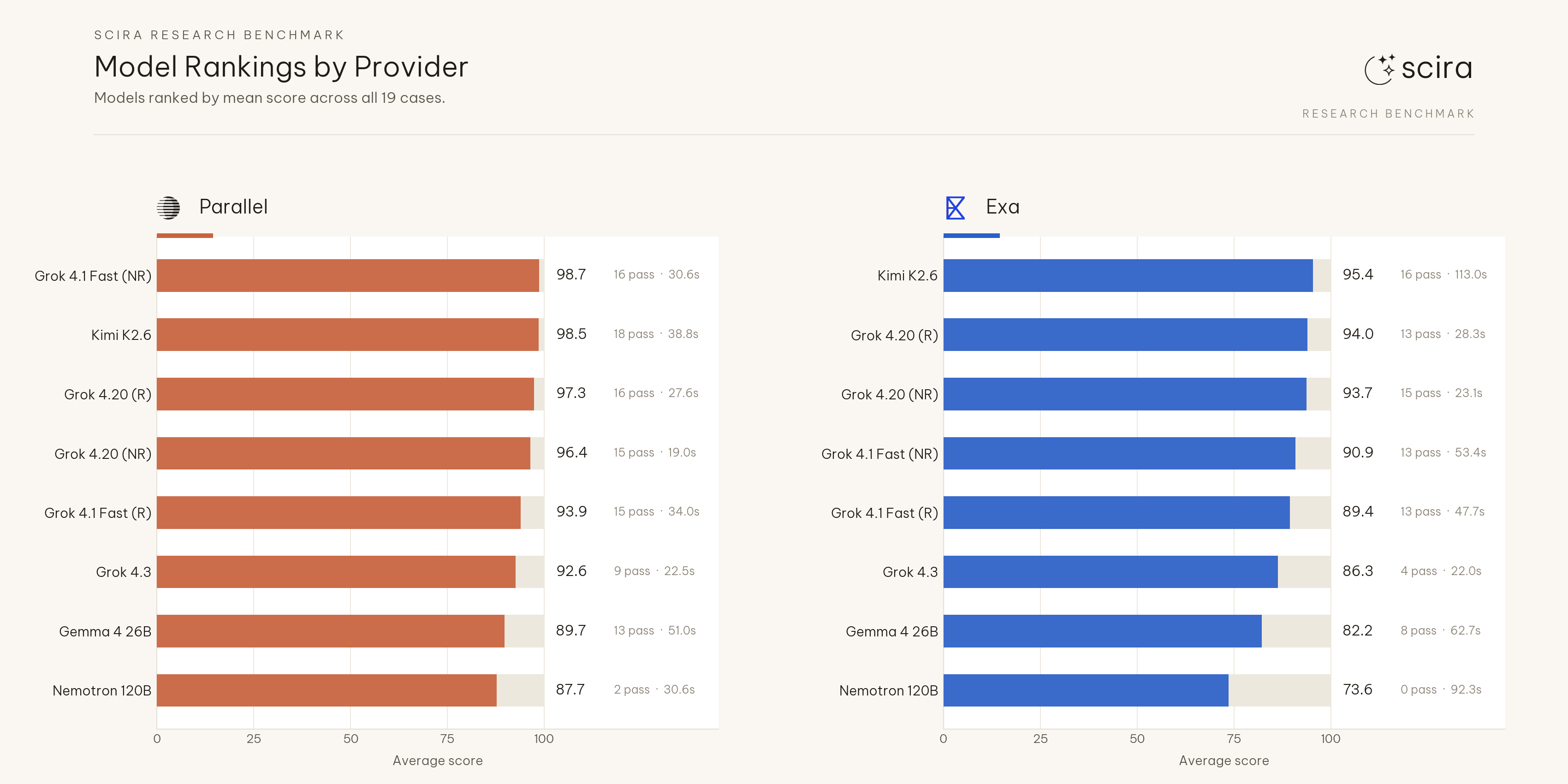 Model rankings by provider
Model rankings by provider
Limits#
- Single run. No repeated suites or bootstrap; numbers will drift with the live web.
- Live web. Rankings and fetched pages change between runs.
- Pass threshold 100. Many cells land at partial credit (often 70-92); compare means, not pass counts alone.
- N = 19 prompts. Suited to coarse gaps (about ten points or more), not hair-splitting among tight Parallel leaders.
- Coverage. Short factual and light browse cases only for now; long-context and multilingual cases are not represented yet.
Reproducing this#
git clone https://github.com/zaidmukaddam/scira-cli-harness
cd scira-cli-harness
bun install
cp .env.example .env.local # add PARALLEL_API_KEY, EXA_API_KEY, model keys
bun run build
bun run src/cli.ts benchmark \
--suite benchmarks/research-smoke.json \
--providers parallel,exa \
--models xai/grok-4-1-fast-non-reasoning,xai/grok-4-1-fast,xai/grok-4.20-0309-non-reasoning,xai/grok-4.20-0309-reasoning,xai/grok-4.3,cloudflare-workers-ai/@cf/moonshotai/kimi-k2.6,cloudflare-workers-ai/@cf/nvidia/nemotron-3-120b-a12b,cloudflare-workers-ai/@cf/google/gemma-4-26b-a4b-it \
--concurrency 4 \
--json --out benchmark-results/scira-bench-$(date +%d%m%Y).jsonImplications for Scira#
- Parallel stays the default grounded-QA search backend until another backend clears this suite on Scira’s target workloads.
- Latency-sensitive paths can default to Grok 4.20 (NR) for a strong mean score with low mean duration on Parallel in this table, or Grok 4.1 Fast (NR) if mean score is the only target.
- The suite reflects chosen prompts and rubrics; adding long-context and multilingual cases should change ordering.
